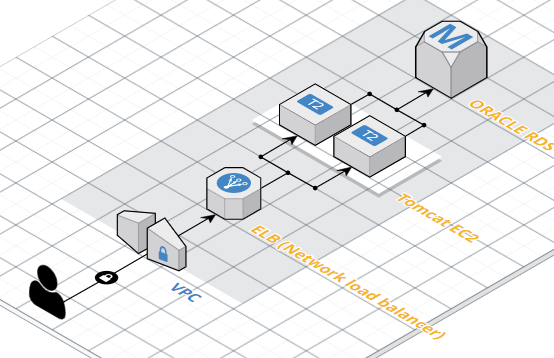
안녕하세요. 검색엔진을 개발하는 이슈가 생겨 현재의 인프라 환경에 적합한 오픈소스를 찾다 Apache Lucene을 알게 되었고, 개발하게 되었습니다. 그리고, Lucene을 적용하기 위해 레퍼런스와 여러 문서들을 찾으면서, 새로운 의문점들이 생겨났습니다. 정말 이 검색엔진이 가장 좋은가? 성능 면에서 어떤 검색엔진 오픈소스가 더 뛰어난가? 어떤 검색엔진 오픈소스가 관리하거나 구축하기 쉬운가? 해당 질문에 대해 항상 명확하고 적용 가능한 답변이 있는 것은 아니지만 어느 목적으로 사용하느냐에 따라 보다 나은 혹은 올바른 선택을 하는데 도움이 될 것입니다. Lucene를 이용하여 검색엔진을 개발을 완료한 지금 뭔가 더 좋은 검색엔진으로 업그레이드 하고 싶은 욕심이 생겨 다시 비교분석을 해보게 되었습니다. 위..