
지난 포스팅에 OPEN Source를 이용한 검색엔진에 대한 기본적인 내용을 공유 하였고
이번 회차에서는 검색엔진의 수집, 색인, 검색에 대한 내용에 대해 상세히 공유 하도록 하겠습니다.
수집 – 검색엔진의 목적에 맞게 사용자가 필요로 하는 정보를 준비하는 과정

- 다양한 형태로 존재하는 비정형 데이터(정보)를 필요에 따라 추출
- 가장 많이 사용되는 웹 페이지 크롤링과 DBMS에 저장된 데이터를 수집하는 과정을 통해 예를 들어 설명
1. 크롤링
웹 페이지를 그대로 가져와서 데이터를 추출해 내는 행위. 크롤링을 하는 소프트웨어를 크롤러라고 부름
- 검색 엔진에서는 웹 상의 다양한 정보를 자동으로 검색하고 색인하기 위해 사용.
- 일일이 해당 사이트의 정보를 검색하는 것이 아닌 끊임없이 새로운 웹 페이지를 찾아 종합하고 찾은
결과를 이용해서 또 새로운 정보를 찾아 색인을 추가하는 작업을 반복 수행

[크롤링 흐름도]
2. Apache Nutch
웹 사이트 크롤링을 위한 오픈 소스 웹 크롤러 소프트웨어 프로젝트
- Apache Lucene을 기반으로 만들어졌기 때문에 독립적으로 수집, 색인, 검색 가능 하고 하지만
특수한 데이터 수집과 다양한 검색을 활용하기 위해 Solr를 함께 사용
Nutch Crawler Architecture
- Crawler는 페이지를 수집하고 페이지에 대한 index를 만들고 Searcher는 유저의 요청을 받아서
필요한 정보를 찾아 보여주는 역할
가. Segment – Crawler에 의해 수집되고 인덱스된 페이지의 모음
나. Fetch list – segment로부터 추출한 URL 목록
다. Index – 가져온 모든 페이지를 색인화 한 것으로 각각의 세그먼트 색인들을 병합
(1) 수집이 최초로 시작될 seed URL 설정
(2) 새로운 segment로부터 fetchlist를 생성
(3) Fetchlist의 URL로부터 Page를 수집
(4) 수집된 Page로부터 링크를 얻어옴
(5) 2~4단계 반복
(6) 중요도와 link정보를 update
(7) 수집한 페이지의 색인 생성
(8) 색인으로부터 중보된 페이지를 제거

[크롤로 흐름도]
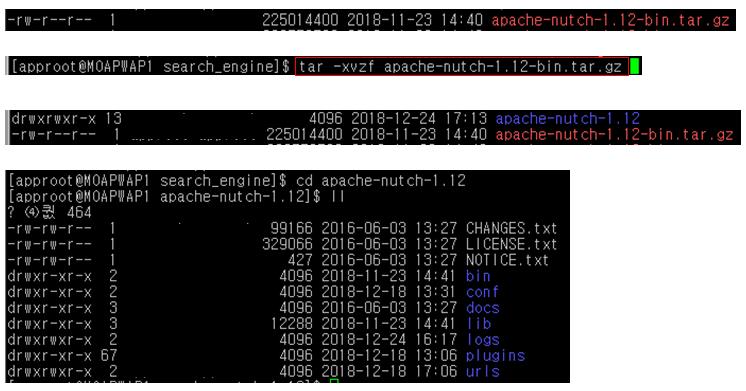
Apache Nutch 설치
- Apache Nutch 공식홈페이지 (http://nutch.apache.org) 에서 ‘apache-nutch-X.XX-bin.tar.gz’ 파일 다운로드
- 설치 파일 압축 풀기
- ${APACHE_NUTCH_HOME}/conf/nutch-site.xml
가. Nutch 프로젝트 설정 파일
나. 반드시 ‘http.agent.name ‘ property에 값을 입력해야 실행 가능
다. 그 외 크롤링 컨텐츠의 크기 제한(http.content.limit), 외부링크 개수제한(db.max.outlinks.per.page)등 설정

- ${APACHE_NUTCH_HOME}/urls/seed.txt
크롤링 시 검색할 첫 사이트를 설정
- ${APACHE_NUTCH_HOME}/conf/regex-urlfilter.txt
정규표현식을 사용해 크롤링 할 사이트를 필터링
Nutch 크롤링 실행 방법
- 크롤링 수행할 첫 URL 설정
(${APACHE_NUTCH_HOME}/urls/seed.txt)
- 크롤링 실행
(${APACHE_NUTCH_HOME}/bin/crawl urls/seed.txt [생성될 크롤링 디렉토리명] [반복횟수])
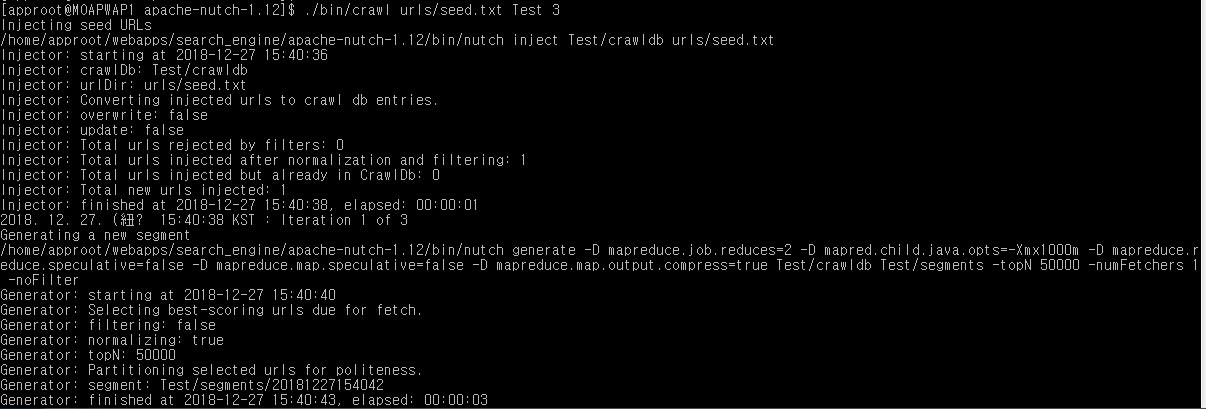
- 세그먼트 확인
(${APACHE_NUTCH_HOME}/bin/crawl urls/seed.txt [생성될 크롤링 디렉토리명] [반복횟수])
3. Apache Solr
Http 요청에 대한 처리와 응답을 하는 웹 기반 검색엔진
- Apache Lucene을 기반으로 만들어져 색인과 검색은 Lucene 엔진을 사용
- 기본적인 UI를 제공하고 독립적인 서버로 구현되어 있기 때문에 사용에 용이
Apache Solr 설치
- Apache Solr 공식홈페이지 (http://lucene.apache.org/solr/) 에서 ‘solr-X.X.X.tar’ 파일 다운로드
- 설치 파일 압축 풀기
- 실행

Solr Dataimport 실행 방법
- JDBC 라이브러리 추가 ( ${APACHE_SOLR_HOME}/server/lib/ )
- 설정 파일에 Dataimport Handler 추가 ( ${APACHE_SOLR_HOME}/server/solr/[Core]/conf/solrconfig.xml)
- data-config.xml 작성
(solrconfig.xml 파일의 경로에 생성 ${APACHE_SOLR_HOME}/server/solr/[Core]/conf/data-config.xml)
- managed-schema 파일에 검색 필드 설정
(${APACHE_SOLR_HOME}/server/solr/[Core]/conf/managed-schema)
색인
1. 역색인 - 검색 키워드가 주어졌을 때에 어떠한 문서에서 나타났는지를 알려주는 자료구조
- 특정 주제를 대상으로 매핑하는 색인(Index)와 반대되는 개념으로 역색인(Inverted Index)는 의미가 있는
단어를 기준으로 매핑
- 이러한 이유로 Full Text Search에 훨씬 유리하고 빠름

[색인]

[역색인]
2. 형태소 분석 - 검색에 최적화된 색인파일을 만들기 위한 색인어 추출방식 중 문장의
의미를 가지는 최소단위로 분리하는 과정 (Tokenizer + Filter)
Solr에서 기본으로 제공되는 형태소 분석기는 한글 형태소 분석기는 없으므로 따로 추가해주어야 함

[색인과정]
형태 분석기 추가
- 아리랑 형태소 분석기 다운로드
http://osasf.net/uploads/sw/arirang.lucene-analyzer-6.2-1.1.0.jar
http://osasf.net/uploads/sw/arirang-morph-1.1.0.jar
- Solr 서버에 형태소 분석기 추가
( ${APACHE_SOLR_HOME}/server/solr-webapp/webapp/WEB-INF/lib/ 경로에 다운로드 받은 분석기 업로드 )
- 색인이 필요한 필드에 타입 설정
( ${APACHE_SOLR_HOME}/server/solr/[Core]/conf/managed-schema )
3. 색인 예제
Nutch 크롤링 데이터 색인
- Nutch 크롤러와 Solr 연동하여 데이터 색인
( ${APACHE_NUTCH_HOME}/bin/nutch solrindex [솔라 서버 URL/[core 명]] [디렉토리명/crawldb] -linkdb [디렉토리명/linkdb] [디렉토리명/segments/*] )
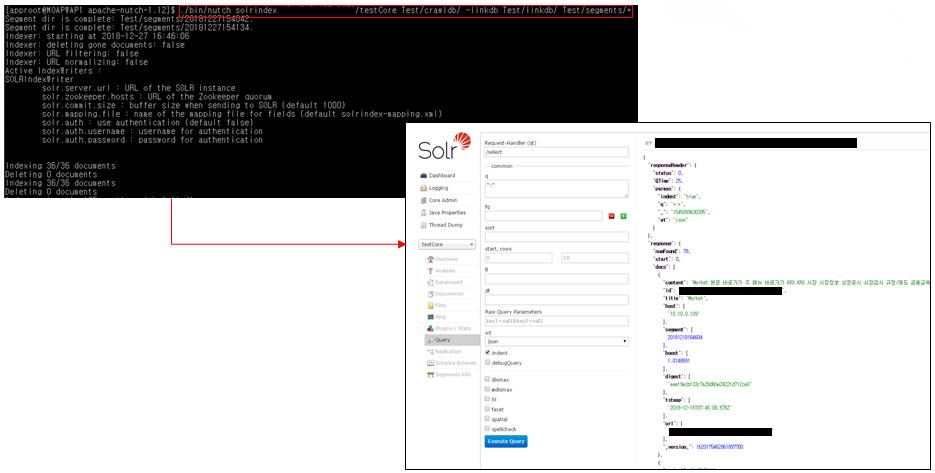
- Solr Dataimport 색인
(Solr 서버 -> Core 선택 -> Dataimport > Excute )
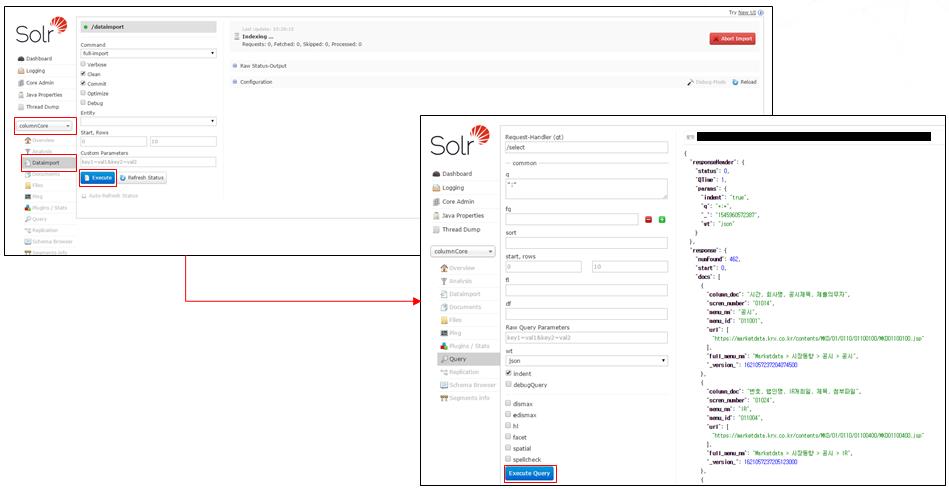
검색
1. Solr를 활용한 기본 검색 방법 (URL 호출)
| Parameter | Default | 설명 |
| Q | - | 검색 쿼리 Ex) q=필드명:검색할 Term [Solr 서버 주소]/[Core명]/select?q=column_doc:시간 |
| Start | 0 | 검색된 결과 리스트의 시작점 |
| rows | 10 | 검색된 결과 리스트의 수 |
| Fl | - | 결과값에 반환 될 필드 Ex) fl=필드명1,필드명2,…. [Solr 서버 주소]/[Core명]/select? q=*:*&column_doc,menu_nm |
| fq | - | 결과 내 검색(AND 조건) Ex) fq=필드명:검색할 Term [Solr 서버 주소]/[Core명]/select?q=column_doc: 시간 &fq=column_doc:정보 |
| Sort | - | 오름/내림차순으로 검색할 필드 지정 Ex) sort=필드명1 (ASC|DESC),필드명2 (ASC|DESC) [Solr 서버 주소]/[Core명]/select?q=*:*&sort=column_doc DESC,menu_nm ASC |
| wt | Xml | 반환된 결과 표출 타입(json, csv, xml 등) Ex) wt=json |
| Hl | 반환된 결과에 검색어 강조 표시 여부 Ex) hl=true |
|
| Hl.fl | 강조 표시를 나타낼 필드 설정 Ex) hl.fl=column_doc |
|
| Hi.simple.post Hl.simple.pre |
<em> </em> |
매칭되는 검색어 앞, 뒤로 삽입할 태그 지정 Ex) hl.simple.pre=<em>&hl.simple.post=</em> |
2. Solr를 활용한 기본 검색 방법 (Java 라이브러리)
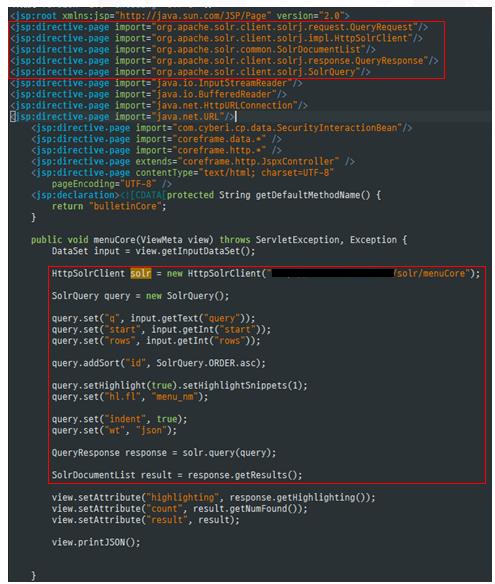
지금까지 검색엔진의 주요 수집, 색인, 검색에 대한 주요 내용 및 OpenSource를 이용하여
개발 하는 방법에 대해 알아 보았습니다.
Open Source 검색 엔진 개발 1편에 대한 내용을 살펴보고 싶다면, 아래 링크를 클릭해주세요.

'유용한 정보' 카테고리의 다른 글
| 성능 TEST를 위한 보고서 2 (0) | 2019.06.28 |
|---|---|
| 성능 TEST를 위한 보고서 1 (0) | 2019.06.18 |
| OPEN Source를 이용한 검색엔진 개발(1) (1) | 2019.03.12 |
| java10 및 서블릿 jsp 어플리케이션 구조 (0) | 2018.09.28 |
| 오라클 자바 라이선스 정책 변경 이슈 (0) | 2018.09.14 |